There is a concept in marketing called the long tail that was originally explained in the magazine Wired.
The concept is rather simple, and when applied to a SharePoint
implementation, it can help you understand why information that is held
in SharePoint isn’t necessarily more findable than information in a
database or a file server.
In short, the concept is that, given the total number of items in a population set that can
be found, the majority of those items will be seldom requested, while a
minority of those items will be frequently requested. For example, most
of your users are likely to visit your intranet portal, but only a
minority of your users will visit any specific team site. But in most
implementations, the number of team sites utilized will be far larger
than the number of frequently accessed sites, like an intranet portal.
The relationship is necessarily inverse and is illustrated in Figure 1.
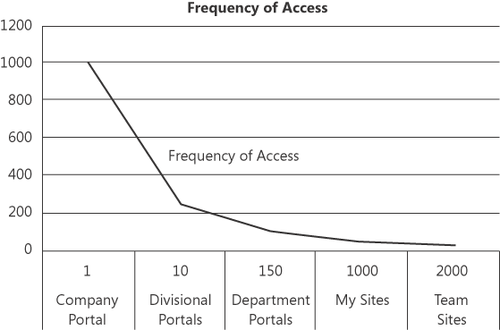
When you realize that
most of the sites, lists, and libraries that are created in a typical
SharePoint 2010 implementation are seldom accessed by more than a
handful of people, the planning issues for a SharePoint 2010
implementation take on important dynamics.
Although you will want to
ensure that your heavily accessed portals are well planned, you should
spend a similar amount of time ensuring that important information
hosted in infrequently accessed team sites is just as accessible and findable.
The core of those planning issues should answer questions such as the following.
How will users who frequently access team sites find those team sites?
How will users who infrequently access team sites find those team sites?
How will users who infrequently access team sites know what information is in those sites?
How will users find documents corporate-wide when conducting an exhaustive search for a specific type of information?
How will users find documents when looking for a sample of data that need not constitute an exhaustive search?
Should
you provide a federated navigation hierarchy for users to browse to
find information? If so, how should you implement this?
These and other questions
begin to get to the heart of findability within SharePoint 2010. Because
most of what is created in SharePoint is in the long tail, most people
who utilize SharePoint will not consume most of the information within
the SharePoint 2010 implementation. Yet your implementation must make all
of the information findable by a potentially large number of your users
(assuming those users have permissions and a need to see the
information).
Finding information merely by
the document’s content will not work in environments in which the data
set is large. In most organizations, the use of words tends to be
homogeneous, meaning that people in an organization tend to use a
certain set of words repeatedly in their documents. For example, an
accounting firm is likely to use a different set of words in its
documents than a medical firm or a marketing firm, but within each of
these companies, the employees will use the same words over and over
again. When words are used in similar ways across multiple documents,
those words lose their effectiveness at discriminating between
documents. You enter a keyword in a query to discriminate between
documents and find the specific one you want, but if the keyword you use
is one that is used by all employees and appears frequently in many
documents, it is really useless as a discriminatory tool.
Moreover, sometimes the same
word can be used across multiple documents with very different meanings.
For example, is it a horn (beep-beep), or a horn (a trumpet), or a horn
(on an animal)? You might enter the keyword “horn” when you are looking
for a document about a trumpet. But if you get a result set full of
content items pointing to a car horn, then—even though the result set
might be syntactically accurate—it will be irrelevant to you. What users
want when they search for information is more than just a result set
that matches their query—they want meaning
within information. To the extent that the content items are meaningful
to them (as well as useful and accessible), then they will view the
result set as relevant.
Defining meaning
in a query is best achieved through a complex query that not only
requests documents with certain keywords but also specifies documents
that have certain metadata characteristics. For example, you might be
looking for the project budget for Customer A. You would normally expect
that this document would contain the word “budget” along with the
customer’s name. However, it’s also possible that the budget document
doesn’t contain the word “budget.” So what are the possible ways to
query and find this document?
In most environments, people
will query only for keywords that they think (or hope) will exist in
the document. In this example, you would normally query for the
following words
If the document had
metadata attached to it, you could further refine your query—if the
metadata has been completed—by using the following criteria.
Security level: “Confidential”
Project name: “SharePoint 2010 Implementation for Customer A”
Project lead: “Bill English”
Project type: “Consulting”
You can see that by adding
several metadata fields to the project budget document and then
including those fields in your query (using the Advanced Query Web
Part), you can be more confident of finding the document that you really
need. More to the point, the better you can define the document that
you’re trying to find, the better you can inform the SharePoint 2010
search technologies of what you mean
with your query. For example, if your company had completed 20 projects
with Customer A, then merely querying for the words “budget” and
“Customer A” would return at least 20 different results, 19 of which
would likely not be relevant to your search. Moreover, depending on how
information is managed, these two words could return hundreds of false
positives, spurious results that lack relevancy to what you are looking
for. But if you can enter the project name, the security level, and the
current project lead (assuming that the project lead is different for
different projects with this customer), then you help define what you mean by the keyword query of “budget” and “Customer A” with further, more discriminatory information.
For metadata to be helpful in finding information, the metadata must be
discriminatory
input accurately
input consistently
defined
Referring back to the
discussion about the word “horn” and how it can have different meanings,
the same principles hold true for metadata. For metadata to be
discriminatory, the metadata words that are entered must have a specific
meaning that is understood by all who use that metadata. In addition,
those meanings must have discriminatory power between documents in
either a stand-alone capacity or when used in conjunction with other
metadata.
For example, assume you have three standard metadata fields that must be applied to each document, as follows.
Security level
Project name
Department name
Each of these three
metadata fields will have some discriminatory abilities when used by
themselves. For example, assume you’re looking for the budget file for
Project A and the file’s security level has been set to “confidential.”
If you enter the keyword “budget” and the security level “confidential,”
you’ll get back results that include any budget for any project across
all departments that has a security level of “confidential.” So a single
metadata field can have discriminatory abilities.
But you’ll find that if you set
up your metadata correctly, combining multiple metadata fields into the
same query can return a much more relevant and concise result set. For
example, if you enter the keyword “budget” and then enter “confidential”
for the security level, “project A” for the project name, and
“Information Technology” for the department name, you’re assured that
the results will only include those documents that have the word
“budget” plus the three metadata values included in your query. That
result set is likely to be much more focused and relevant because it is
better defined.
For metadata to be meaningful,
both the metadata field names and the range of potential values have to
be defined and distributed. Hence, a glossary is needed to define the
meaning of both the field names and the metadata values. And then the
glossary needs to be distributed and utilized as a business tool.